How to make a github actions matrix for your Ginkgo tests
2024-02-25
If you’ve ever dabbled in writing or maintaining a Kubernetes operator using kubebuilder or operator-framework, you’ll surely know what Ginkgo is.
For everyone else: Ginkgo (paired with Gomega) it’s the default kubebuilder/operator-framework suite for writing integration/e2e tests.
And most likely, you’ve also worked with this framework in GitHub Actions and noticed how frustrating it can be to wait for a long test job to finish, perhaps reporting errors that need to be read in lengthy log outputs. Nothing irreparable, of course, but when you have a single flaky test, it can consume all your time and invalidate the entire pipeline.
Getting to know Ginkgo better
While studying the framework for an operator I am currently maintaining, I came across an important statement in the documentation:
[…] Ginkgo makes an important, foundational, assuption about the specs in your suite: Ginkgo assumes specs are independent. Because individual Ginkgo specs do not depend on each other, it is possible to run them in any order; it is possible to run subsets of them; it is even possible to run them simultaneously in parallel. Ensuring your specs are independent is foundational to writing effective Ginkgo suites that make the most of Ginkgo’s capabilities.
The idea
Indeed, I noticed that the tests were executed randomly in a different order each time. With a random namespace in the code, I thought to myself, “Why not run them in parallel?” The issue with that approach is that each test spawned a Jenkins instance, and having 3-6 of them could overload a single GitHub runner. While the tests might succeed, the pressure on the cluster could slow down or halt execution altogether.
So, my second thought was, “Why not run them separately in a GitHub Actions matrix?” This way, if a job fails, I can simply restart that particular one without rerunning all of them.
GitHub Actions Matrix and JSON
What is this github actions matrix anyway?
The GitHub Actions matrix lets you run your workflow tasks across different configurations in a single YAML file. It’s handy for testing on various setups simultaneously. Here’s a quick example snippet:
jobs:
build:
strategy:
matrix:
os: [ubuntu-latest, windows-latest, macos-latest]
python-version: [3.7, 3.8, 3.9]
runs-on: ${{ matrix.os }}
steps:
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: ${{ matrix.python-version }}
In this example, tasks would run across Ubuntu, Windows, and macOS using Python versions 3.7, 3.8, and 3.9, testing different combinations efficiently.
Free form matrix and fromJson
Some time ago, the only way to create matrices in GitHub Actions syntax was with hardcoded values or by using specific GitHub Actions.
This changed a while ago when GitHub introduced the fromJson method. This was a game changer because it allowed you to create dynamic jobs based on pre-generated output.
Parsing with an old ginko version problem
Goal
Now it comes the fun part, to create a matrix we need to produce a json output with the list of ginkgo tests and then split them and tell ginkgo to only run of them with the ginkgo.focus option.
My first thought was to see in the upstream documentation what I can use to generate -without running the tests- a parsable report or even better a JSON one. However my operator is still in the middle of golang/SDK upgrade, so I have to deal with a very old version of Ginkgo (v1.14.1) with limited options.
Tentative #1: ginko.dryRun
The first tentative was to use the ginkgo.dryRun option that will list all the tests, let’s see the output for the helm test directory:
$ go test -parallel=1 ./test/helm/ -ginkgo.v -ginkgo.dryRun -v
=== RUN TestHelm
Running Suite: Controller Suite
===============================
Random Seed: 1708904511
Will run 3 of 3 specs
Jenkins Controller Deploys jenkins operator with helm charts with default values
Deploys Jenkins operator and configures the default Jenkins instance
/home/player1/repo/kubernetes-operator/test/helm/helm_test.go:39
•
------------------------------
Jenkins Controller with security validator When Jenkins CR contains plugins with security warnings
Denies creating a jenkins CR with a plugin contains security warning
/home/player1/repo/kubernetes-operator/test/helm/helm_test.go:102
•
------------------------------
Jenkins Controller with security validator When Jenkins CR doesn't contain plugins with security warnings
Permit creating a jenkins CR without security warning in plugins
/home/player1/repo/kubernetes-operator/test/helm/helm_test.go:124
•
Ran 3 of 3 Specs in 0.000 seconds
SUCCESS! -- 0 Passed | 0 Failed | 0 Pending | 0 Skipped
--- PASS: TestHelm (0.00s)
PASS
ok github.com/jenkinsci/kubernetes-operator/test/helm 0.013s
As you can see, it lists all the tests with the context and the file:line where the test is located. This is great, as it contains all the info we need, however, it’s hard to parse because it also has some other output that is not necessary. Maybe a couple of openapi API calls will help me to create multiple regex to extract the info I need, but I decided to go for a simple route.
Tentative #2: the old but reproducible grep
The second tentative, that at the end was the one I decided to use, is to simple search in the tests file for It() that is the ginko test case specification (called subject node):
$ grep -rE 'It\([^)]+\)' test/helm/
test/helm/helm_test.go: It("Deploys Jenkins operator and configures the default Jenkins instance", func() {
test/helm/helm_test.go: It("Denies creating a jenkins CR with a plugin contains security warning", func() {
test/helm/helm_test.go: It("Permit creating a jenkins CR without security warning in plugins", func() {
Okay, nice, now let’s also use -n to grab the line for each file:
$ grep -nrE 'It\([^)]+\)' test/helm/
test/helm/helm_test.go:39: It("Deploys Jenkins operator and configures the default Jenkins instance", func() {
test/helm/helm_test.go:102: It("Denies creating a jenkins CR with a plugin contains security warning", func() {
test/helm/helm_test.go:124: It("Permit creating a jenkins CR without security warning in plugins", func() {
Okay, so now we have for each directory the list of ginkgo tests, the file where they are defined, and the line.
Cool, now let’s find a way to make the entire output as JSON so we can use it in our GitHub Actions matrix.
Little hack for the rescue
To convert everything to JSON, I used a little bash script (which I also use in other places with the same scope). Let’s see it together:
#!/usr/bin/env bash
TESTDIR="${TESTDIR:-test}"
json_output(){
lastl=$(echo "${1}" | wc -l)
line=0
printf '{\"include\":['
while read -r test; do
line=$((line + 1))
grep_info=$(echo "${test}"|awk -F '"' '{print $1}')
f=$(echo "${grep_info}"|cut -d ':' -f 1)
l=$(echo "${grep_info}"|cut -d ':' -f 2)
t=$(echo "${test}"|awk -F '"' '{print $2}')
printf '{\"file\":\"%s\",\"line\":\"%s\",\"test\":\"%s\"}' "$f" "$l" "$t"
[[ $line -ne $lastl ]] && printf ","
done <<< "${1}"
printf "]}"
}
parse(){
grep -nrE 'It\([^)]+\)' "$1"
}
tests_list=$(parse "${TESTDIR}"/"${1}")
json_output "${tests_list}"
The most important part is the json_output function, github will require afaik a include as top priority json key and a list of child object that will injected in each job. The function is easy to read, but in case it’s not obvious, I will explain it very quickly:
This function is the parser with grep we saw before:
parse(){
grep -nrE 'It\([^)]+\)' "$1"
}
on the last 2 lines we are running the parse function agains the directory where the tests are located (the argument of the script) and pass it to the json_output function:
json_output(){
lastl=$(echo "${1}" | wc -l)
line=0
Here we are just counting the lines and setting a counter so we can understand when the last object of the output is ending the loop.
printf '{\"include\":['
while read -r test; do
line=$((line + 1))
grep_info=$(echo "${test}"|awk -F '"' '{print $1}')
f=$(echo "${grep_info}"|cut -d ':' -f 1)
l=$(echo "${grep_info}"|cut -d ':' -f 2)
t=$(echo "${test}"|awk -F '"' '{print $2}')
printf '{\"file\":\"%s\",\"line\":\"%s\",\"test\":\"%s\"}' "$f" "$l" "$t"
[[ $line -ne $lastl ]] && printf ","
done <<< "${1}"
printf "]}"
With the firts and the last printf we are just opening and closing the json object.
The main loop will take each line and split it using awk to extract the test name and the rest of the info:
fis the filenamelthe linetis the proper test name withouth theit()
Like I said, it’s straightforward.
Result
$ test/make_matrix_ginkgo.sh helm |jq .
{
"include": [
{
"file": "test/helm/helm_test.go",
"line": "39",
"test": "Deploys Jenkins operator and configures the default Jenkins instance"
},
{
"file": "test/helm/helm_test.go",
"line": "102",
"test": "Denies creating a jenkins CR with a plugin contains security warning"
},
{
"file": "test/helm/helm_test.go",
"line": "124",
"test": "Permit creating a jenkins CR without security warning in plugins"
}
]
}
Nice! now let’s put everything togheter in our github action workflow.
GitHub Action Config
The matrix creation
The first job will be the one that creates the matrix. Here’s an example snippet:
jobs:
create-helm-list:
name: HELM Create tests list
runs-on: ubuntu-latest
outputs:
matrix: ${{ steps.matrix.outputs.matrix }}
steps:
- uses: actions/checkout@v4
- id: matrix
run: |
script=$(./test/make_matrix_ginkgo.sh helm)
echo "matrix=${script}" >> $GITHUB_OUTPUT
This job runs our script against our selected directory and creates a variable called matrix with the output of our script.
Before creating the actual matrix, you can have other jobs for tasks not necessarily linked with the Ginkgo tests, such as formatting, verification, or unit tests.
Now, let’s create the matrix:
run-helm-tests:
runs-on: ubuntu-latest
needs: [create-helm-list]
if: github.event.pull_request.draft == false
name: HELM ${{ matrix.test }}
strategy:
fail-fast: false
matrix: ${{ fromJSON(needs.create-helm-list.outputs.matrix) }}
steps:
- name: Check out code
uses: actions/checkout@v4
[...]
- name: Jenkins Operator - Helm Chart tests
env:
TNAME: ${{ matrix.test }}
TFILE: ${{ matrix.file }}
TLINE: ${{ matrix.line }}
run: |
printf "\n \n > Running test: %s from file: $s line: %s\n" "${TNAME}" "${TFILE}" "${TLINE}"
make helm-e2e E2E_TEST_ARGS='-ginkgo.v -ginkgo.focus="${TNAME}"'
Line by line:
needs: sets ourcreate-helm-list(matrix creation job) as a prerequisite for this job.if: runs the job only if the pull request is not a draft.name: sets the name with the test name, which is the first matrix occurrence.strategy.matrix: utilizes the JSON created in the previous step to actually create the matrix.steps.run: contains a debug print line with all the info (name, file, and line) and passes the test name to Ginkgo for execution as one of the jobs in the matrix list.
Before/After
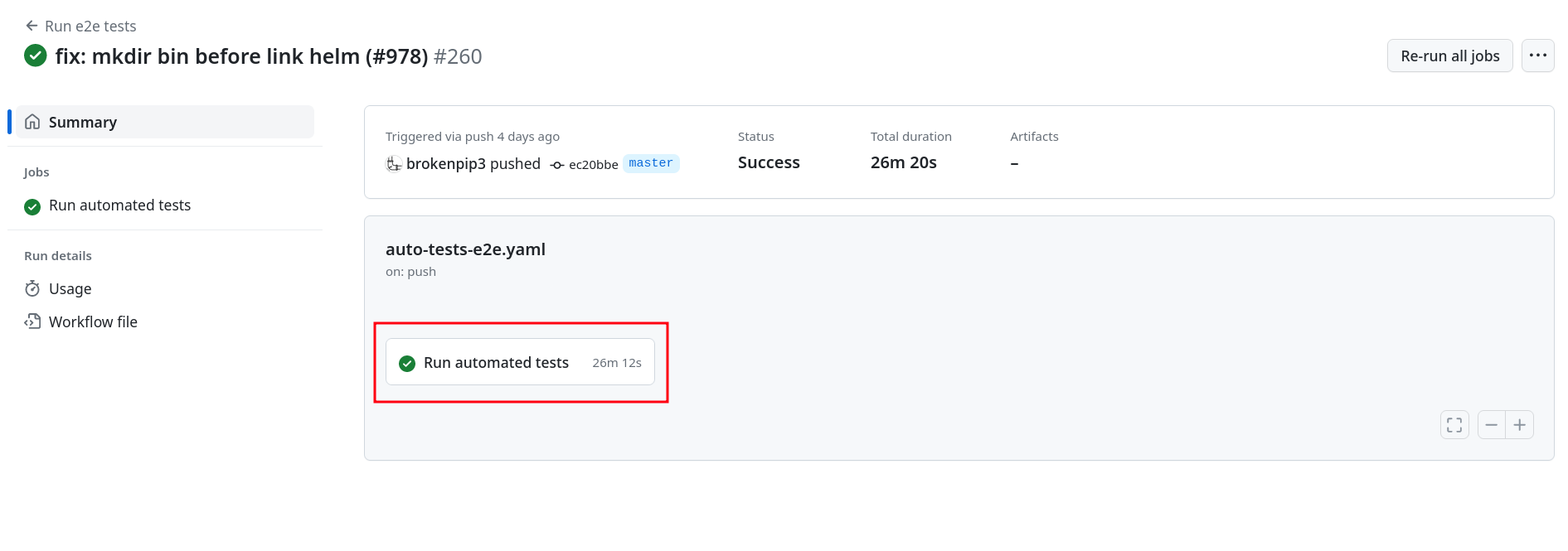
Here you can find some meaningful screeshots:
before, single execution:
after with matrix:
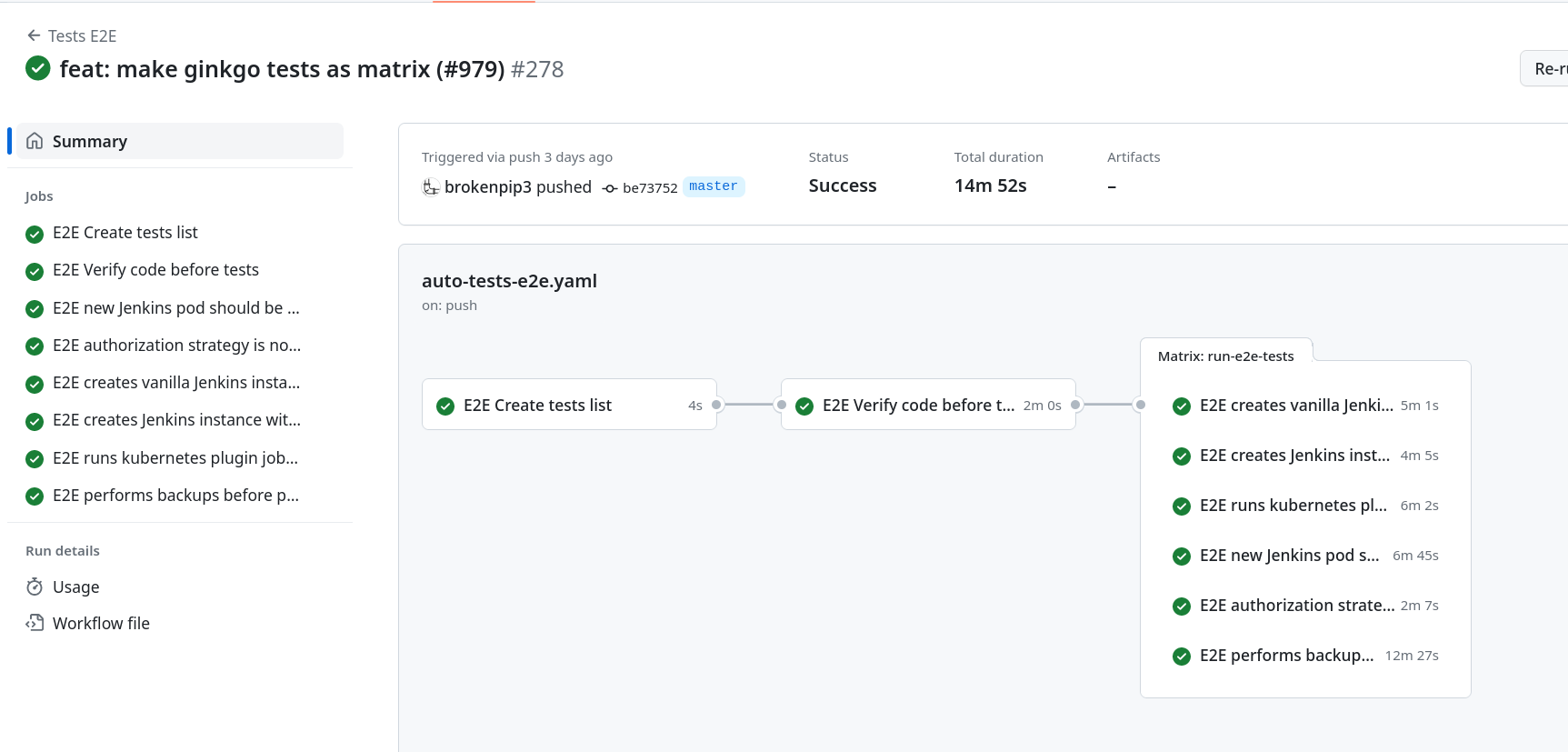
Profit!
Downsides
We also have some downsides that are worth mentioning:
Losing the context info: Unfortunately, with this old version of
ginkgo, we were forced to extract the test in a forceful way, and we lost one piece of information: the ginkgo context. After the upgrade, I will definitely reconsider taking a look at the ginko options of the new version so I can also consider the context in the matrix list.Meaningful and different names: By pursuing this approach, all the
subject nodeneeds to have a unique name.